|
|
@@ -1,14 +1,13 @@
|
|
|
# Frigate - Realtime Object Detection for IP Cameras
|
|
|
-**Note:** This version requires the use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/)
|
|
|
-
|
|
|
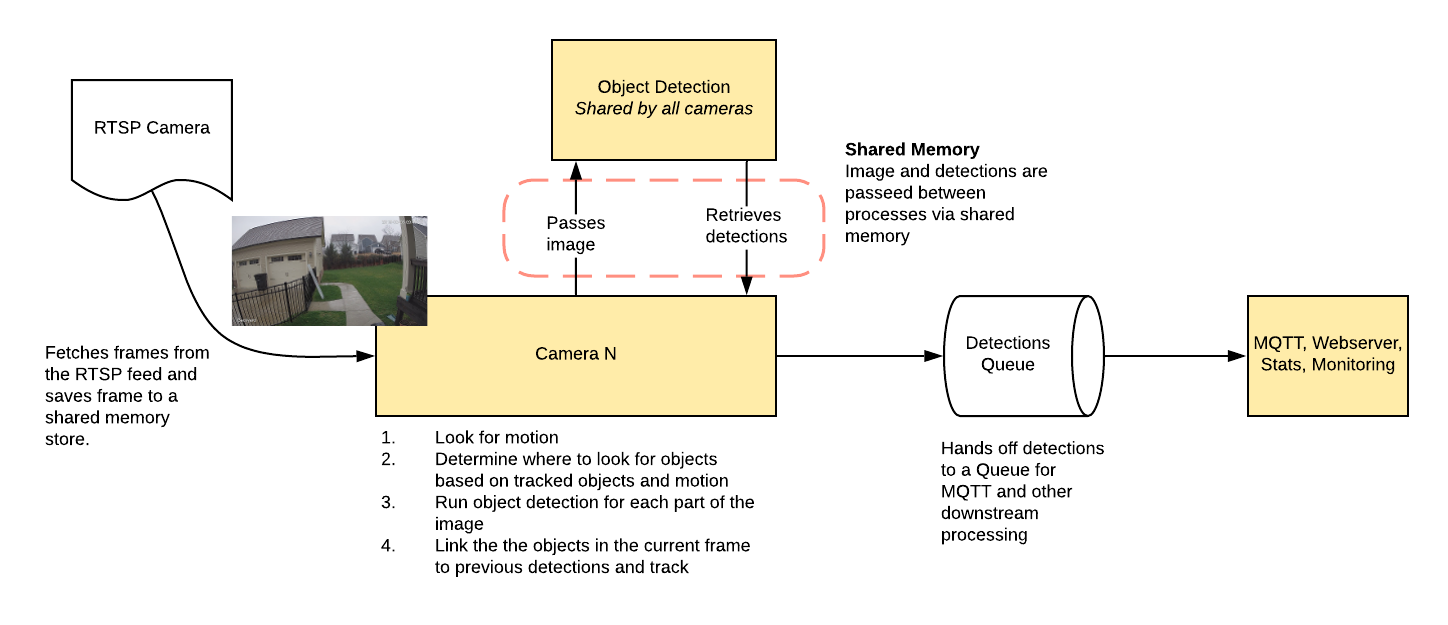
Uses OpenCV and Tensorflow to perform realtime object detection locally for IP cameras. Designed for integration with HomeAssistant or others via MQTT.
|
|
|
|
|
|
-- Leverages multiprocessing and threads heavily with an emphasis on realtime over processing every frame
|
|
|
-- Allows you to define specific regions (squares) in the image to look for objects
|
|
|
-- No motion detection (for now)
|
|
|
-- Object detection with Tensorflow runs in a separate thread
|
|
|
+Use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/) is optional, but highly recommended. On my Intel i7 processor, I can process 2-3 FPS with the CPU. The Coral can process 100+ FPS with very low CPU load.
|
|
|
+
|
|
|
+- Leverages multiprocessing heavily with an emphasis on realtime over processing every frame
|
|
|
+- Uses a very low overhead motion detection to determine where to run object detection
|
|
|
+- Object detection with Tensorflow runs in a separate process
|
|
|
- Object info is published over MQTT for integration into HomeAssistant as a binary sensor
|
|
|
-- An endpoint is available to view an MJPEG stream for debugging
|
|
|
+- An endpoint is available to view an MJPEG stream for debugging, but should not be used continuously
|
|
|
|
|
|

|
|
|
|
|
|
@@ -22,12 +21,16 @@ Build the container with
|
|
|
docker build -t frigate .
|
|
|
```
|
|
|
|
|
|
-The `mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite` model is included and used by default. You can use your own model and labels by mounting files in the container at `/frozen_inference_graph.pb` and `/label_map.pbtext`. Models must be compatible with the Coral according to [this](https://coral.withgoogle.com/models/).
|
|
|
+Models for both CPU and EdgeTPU (Coral) are bundled in the image. You can use your own models with volume mounts:
|
|
|
+- CPU Model: `/cpu_model.tflite`
|
|
|
+- EdgeTPU Model: `/edgetpu_model.tflite`
|
|
|
+- Labels: `/labelmap.txt`
|
|
|
|
|
|
Run the container with
|
|
|
-```
|
|
|
+```bash
|
|
|
docker run --rm \
|
|
|
--privileged \
|
|
|
+--shm-size=512m \ # should work for a 2-3 cameras
|
|
|
-v /dev/bus/usb:/dev/bus/usb \
|
|
|
-v <path_to_config_dir>:/config:ro \
|
|
|
-v /etc/localtime:/etc/localtime:ro \
|
|
|
@@ -37,11 +40,12 @@ frigate:latest
|
|
|
```
|
|
|
|
|
|
Example docker-compose:
|
|
|
-```
|
|
|
+```yaml
|
|
|
frigate:
|
|
|
container_name: frigate
|
|
|
restart: unless-stopped
|
|
|
privileged: true
|
|
|
+ shm_size: '1g' # should work for 5-7 cameras
|
|
|
image: frigate:latest
|
|
|
volumes:
|
|
|
- /dev/bus/usb:/dev/bus/usb
|
|
|
@@ -57,6 +61,8 @@ A `config.yml` file must exist in the `config` directory. See example [here](con
|
|
|
|
|
|
Access the mjpeg stream at `http://localhost:5000/<camera_name>` and the best snapshot for any object type with at `http://localhost:5000/<camera_name>/<object_name>/best.jpg`
|
|
|
|
|
|
+Debug info is available at `http://localhost:5000/debug/stats`
|
|
|
+
|
|
|
## Integration with HomeAssistant
|
|
|
```
|
|
|
camera:
|
|
|
@@ -93,30 +99,34 @@ automation:
|
|
|
photo:
|
|
|
- url: http://<ip>:5000/<camera_name>/person/best.jpg
|
|
|
caption: A person was detected.
|
|
|
+
|
|
|
+sensor:
|
|
|
+ - platform: rest
|
|
|
+ name: Frigate Debug
|
|
|
+ resource: http://localhost:5000/debug/stats
|
|
|
+ scan_interval: 5
|
|
|
+ json_attributes:
|
|
|
+ - back
|
|
|
+ - coral
|
|
|
+ value_template: 'OK'
|
|
|
+ - platform: template
|
|
|
+ sensors:
|
|
|
+ back_fps:
|
|
|
+ value_template: '{{ states.sensor.frigate_debug.attributes["back"]["fps"] }}'
|
|
|
+ unit_of_measurement: 'FPS'
|
|
|
+ back_skipped_fps:
|
|
|
+ value_template: '{{ states.sensor.frigate_debug.attributes["back"]["skipped_fps"] }}'
|
|
|
+ unit_of_measurement: 'FPS'
|
|
|
+ back_detection_fps:
|
|
|
+ value_template: '{{ states.sensor.frigate_debug.attributes["back"]["detection_fps"] }}'
|
|
|
+ unit_of_measurement: 'FPS'
|
|
|
+ frigate_coral_fps:
|
|
|
+ value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["fps"] }}'
|
|
|
+ unit_of_measurement: 'FPS'
|
|
|
+ frigate_coral_inference:
|
|
|
+ value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["inference_speed"] }}'
|
|
|
+ unit_of_measurement: 'ms'
|
|
|
```
|
|
|
|
|
|
## Tips
|
|
|
- Lower the framerate of the video feed on the camera to reduce the CPU usage for capturing the feed
|
|
|
-
|
|
|
-## Future improvements
|
|
|
-- [x] Remove motion detection for now
|
|
|
-- [x] Try running object detection in a thread rather than a process
|
|
|
-- [x] Implement min person size again
|
|
|
-- [x] Switch to a config file
|
|
|
-- [x] Handle multiple cameras in the same container
|
|
|
-- [ ] Attempt to figure out coral symlinking
|
|
|
-- [ ] Add object list to config with min scores for mqtt
|
|
|
-- [ ] Move mjpeg encoding to a separate process
|
|
|
-- [ ] Simplify motion detection (check entire image against mask, resize instead of gaussian blur)
|
|
|
-- [ ] See if motion detection is even worth running
|
|
|
-- [ ] Scan for people across entire image rather than specfic regions
|
|
|
-- [ ] Dynamically resize detection area and follow people
|
|
|
-- [ ] Add ability to turn detection on and off via MQTT
|
|
|
-- [ ] Output movie clips of people for notifications, etc.
|
|
|
-- [ ] Integrate with homeassistant push camera
|
|
|
-- [ ] Merge bounding boxes that span multiple regions
|
|
|
-- [ ] Implement mode to save labeled objects for training
|
|
|
-- [ ] Try and reduce CPU usage by simplifying the tensorflow model to just include the objects we care about
|
|
|
-- [ ] Look into GPU accelerated decoding of RTSP stream
|
|
|
-- [ ] Send video over a socket and use JSMPEG
|
|
|
-- [x] Look into neural compute stick
|

 Blake Blackshear
Blake Blackshear
{kind=link}